Computational Methods
I love learning about new computational techniques and associated debates. These are my current favorite approaches.
Generalized Linear Mixed Models
Fixed and Random Effects.
Environments and experiments are typically structured, involving multiple decisions made by the same individual and repeated decisions about the same item. In my research, I’ve found it incredibly useful to leverage this structure by treating participants and experimental items as random effects. R's libraries, particularly those designed for mixed-effects models, have been especially effective for this type of analysis.
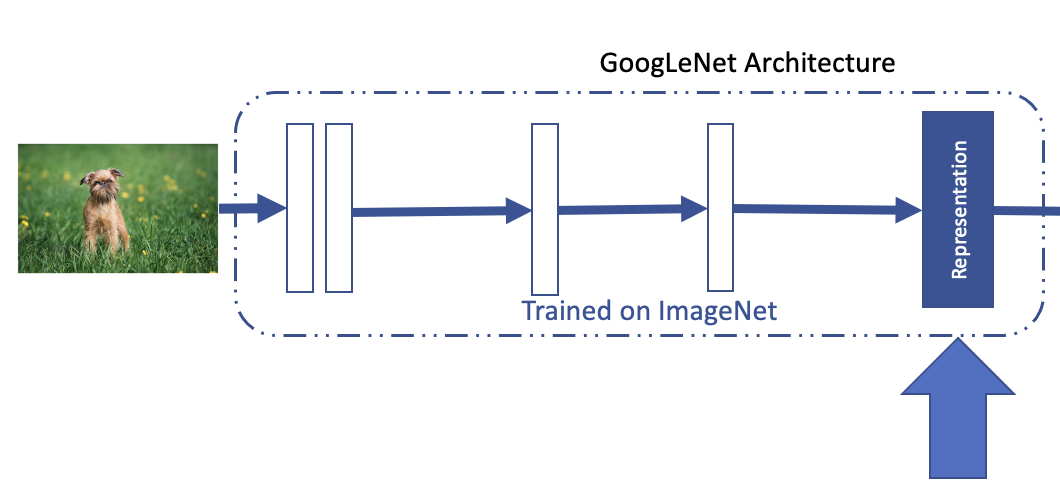
Artificial Neural Networks
Machine Representations/ Embeddings.
The internal layers of a neural network capture essential information about the stimulus, revealing its underlying geometric structure. I'm particularly interested in exploring this structure and investigating the correspondence between human cognition and machine learning models. To dive deeper into this, I recently built a deep learning PC, enabling me to experiment further. I primarily work with PyTorch and have experience training various architectures, including convolutional neural networks, transformers, GANs, and more.
Evidence Accumulation Models
Decision after a threshold.
In evidence accumulation models, decisions are made once the accumulated evidence reaches a specific threshold. Within this framework, various models can be developed to explain the nature of the evidence, how it is accumulated, and the precise moment a decision is triggered. This approach has enabled us to investigate a range of decision biases and the role of attention in decision-making. For these analyses, I primarily use Python and custom code to tailor the models to specific research questions.
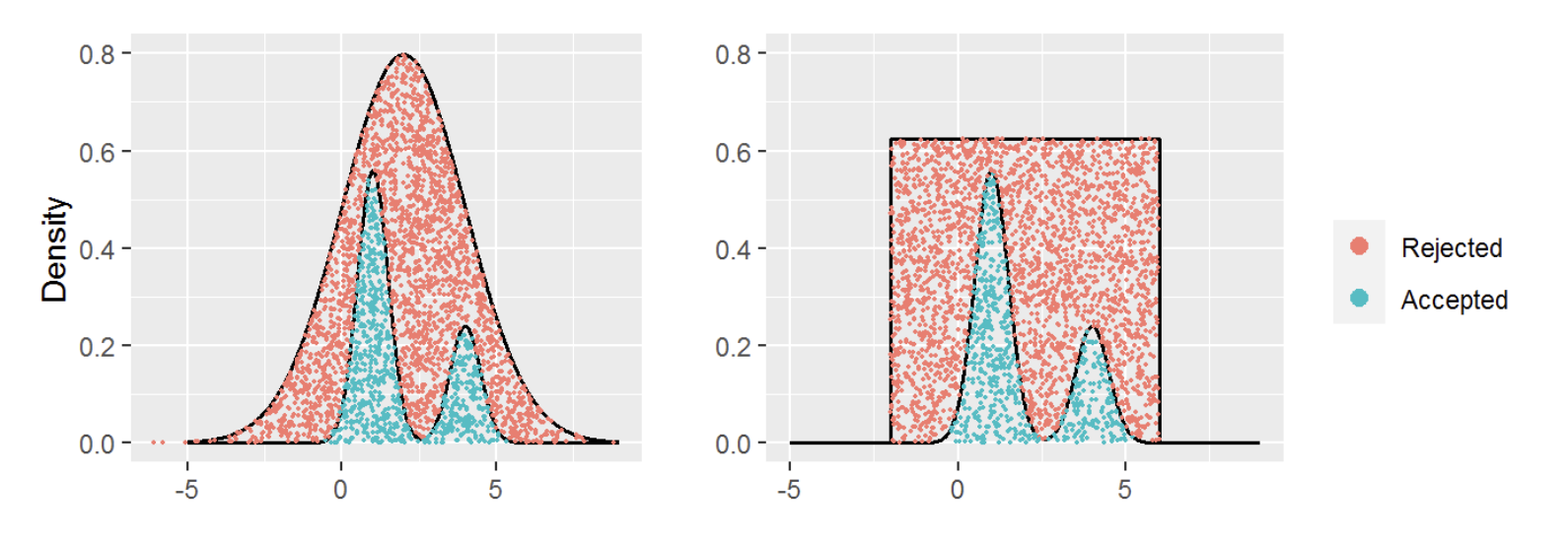
Bayesian MCMC Methods
Quantifying Uncertainty.
Bayesian models provide a natural way to quantify uncertainty in estimates. For most of my Bayesian analysis, I have used PyMC3, though I’ve also developed my own differential evolution MCMC sampler. I thoroughly enjoyed diving into the mechanics of these sampling algorithms, uncovering both their strengths and potential pitfalls. This experience has deepened my understanding of common challenges in inference, such as dealing with correlated parameters, bimodal distributions, and other complexities that arise not only in Bayesian inference but in statistical inference more broadly.